Качая миллион url
Intro
В один прекрасный день захотелось мне что-то накодить интересное в обучающих целях. Так как это только для развлечения, то времени занять это должно не много. Подумал я и решил,а скачаю я за разумное время Alexa Top 1 million sites.
Requirements
- Можно написать за день,максимум 2
- Ограниченный бюджет
- Система горизонтально масштабируема
Недолго думая я решил, что у меня будут воркеры которые качают страницы, и отдельная база, куда будет складываться скачанный контент.
Варианты раздавать задачи cralwer
- Принудительно раздавать задания воркерам, например просто закинуть каждому свой спискок url да и все
- Пусть воркеры приходят за заданиями в redis, например
Я выбрал redis.Быстрый и легкий.Мне хватит с головой.Хранить скачанный контент я буду в NoSQL базе Riak.
Почему Riak?
По правде говоря он мне там нафиг не нужен.Нагрузки нету, кластер строить пока не надо.Но я был очарован ,как он обходит ограничения CAP.Он для сущностей позволяет настраивать на сколько машин должа она реплицироваться,сколько машин должно ответить “ОК,я записал” чтоб riak посчитал что данные записаны.
- есть какая-то интеграция с Solr (в голове у меня возникла красивая картинка,воркеры пишут и оно само переливается в Solr) и я буду еще по этому и искать,красота да и только,и кода меньше нужно писать будет.
Воркеры
Воркеры я решил написать на python 3.5.Также ко всему этому прилагалось Fabric деплоймент система с виду простая и не замороченная. Без деплоя никак,так как я не знал сколько серверов заведу,а настраивать каждый ручками не хочется.
Что получилось?
- Сервер с riak для хранения контента
- redis в качестве очереди задач
- воркеры качающие url ,на python
- Fabric для деплоя
- Возможно еще и поиск по всему этому через Solr
Воркеры
Воркеры писались на python, ничего военного в них абсолютно нет, раз я смог их напилить за денек. Использовались futures и библиотека requests. Так как я не в повседневной жизни Python редко использую,то код не оптимален и страшен =)
def download_urls(self, urls):
with futures.ThreadPoolExecutor(max_workers=self.MAX_WORKERS) as executor:
to_do_map = {}
for url in urls:
url=self._clean_url(url)
future = executor.submit(self.download_content, url)
to_do_map[future] = url
for future in futures.as_completed(to_do_map):
try:
data = future.result()
self.callback(to_do_map[future], data)
logging.info("Site {} has been downloaded with len:{}".format(to_do_map[future], len(data)))
except Exception as exc:
self.queue.wrongurl(to_do_map[future])
logging.error("Failed to download {} with message {}".format(to_do_map[future],exc))Из непонятного здесь только вызов self.callback(to_do_map[future], data) сохраняющий скачанный контент в riak. Скрипт на тестовой машине отлаживал,до тех пор пока в среднем на 1 url не уходило 0.1-0.2 секунды. Т.е. (1000000*0,2)/3600= 55-56 часов,т.е. 2 дня.Одна машина будет качать 55 часов,добавим 2-3 машины сответсвеннно уменьшим время скачки.
Наконецто старт
Итак, напилив код на python проверив его в предварительно настроенном vagrant , решил я на DO взять сервак,за 40 уе в месяц как основной (чтоб винта хватило),а воркеры штуки 3-4 будут у меня за 20 уе.
Поставил на сервак riak и redis.И импортировал в redis этот миллион url(заняло 79 метров).
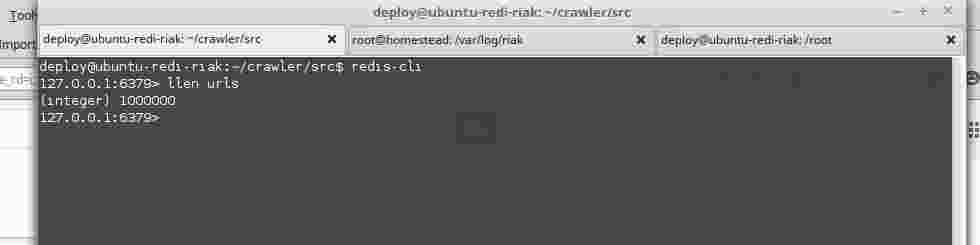 На картинке показана длинна коллекции urls ,1000 000
На картинке показана длинна коллекции urls ,1000 000
Грабли с riak
И в бой.Запустив пару раз скрипт,убедившись, что все на удивление работает,оставил систему.
Вернувшись проверить через пару часов, что ж я увидел? riak упал =(, ну думаю мой косяк,ребутнул его,выставил лимит открытых файлов еще болльше,и запустил все опять!
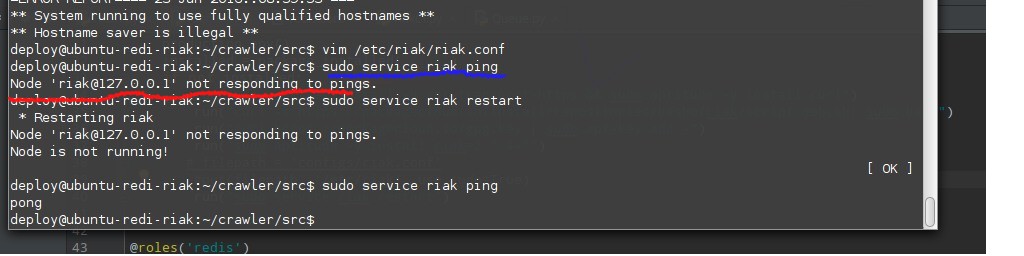 Не тут то было,riak начал иногда падать,и вот мои первые грабли. В доках ясно написано, что в riak нужно вставлять маленькие обьекты,меньше мегабайта.У меня же,иногда размер страницы был больше мегабайта,думаю поэтому riak и падал.
Ну его в баню,думаю и чем отлаживать riak который ел на сервере 3ГБ,или обрезать контент лучше быстро впилить монгу.
Не тут то было,riak начал иногда падать,и вот мои первые грабли. В доках ясно написано, что в riak нужно вставлять маленькие обьекты,меньше мегабайта.У меня же,иногда размер страницы был больше мегабайта,думаю поэтому riak и падал.
Ну его в баню,думаю и чем отлаживать riak который ел на сервере 3ГБ,или обрезать контент лучше быстро впилить монгу.
Mongo
В этот раз я озаботился еще и местом на диске.Хотелось бы чтоб контент еще и сжат был.Недолго погуглив, остановился я на mongo 3.2, так как у нее есть сжатие из коробки (движок wiredTiger по умолчанию). Перепилить с riak на mongo код заняло,часик!Убедившись что все работает ,и mongo не падает как riak,я отправился спать.
Еще грабли
Утром обнаружилось ,что всеж таки mongo надо принудительно настривать на сжатие с компрессией.Зашол я на сервак и удивился,скачано 300 тысяч url, а занято уже гб 30-40.Пришлось разбиратся, оказалось что все сохранялдось в mmapv1 (т.е. memory mapped files) 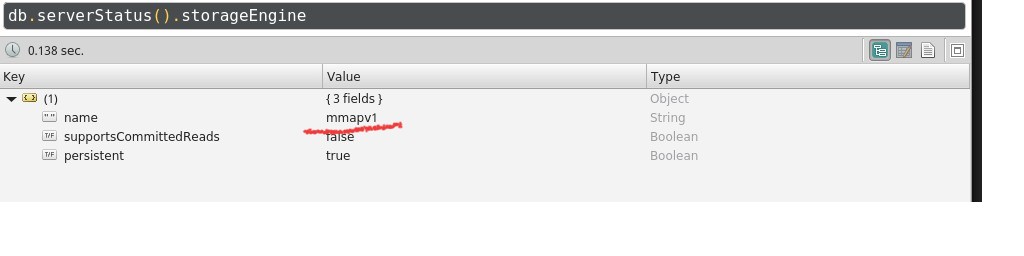 . Эхх, вторые грабли - положиться на дефолтный конфиг. Задавайте явно конфиги,явное лучше неявного,убедился я еще раз.
Пришлось импортировать данные с сервера с gzip сжатием на другой сервак,включить wiredTiger c zlib сжатием и заимпортить все обратно.
. Эхх, вторые грабли - положиться на дефолтный конфиг. Задавайте явно конфиги,явное лучше неявного,убедился я еще раз.
Пришлось импортировать данные с сервера с gzip сжатием на другой сервак,включить wiredTiger c zlib сжатием и заимпортить все обратно.
 Запустив воркеров на этот раз,убедившись что все жмется,и движок действительно wiredTiger,mongo не падает,и вроде все быстренько бегает ,я успокоился и оставил все кравлить.
Запустив воркеров на этот раз,убедившись что все жмется,и движок действительно wiredTiger,mongo не падает,и вроде все быстренько бегает ,я успокоился и оставил все кравлить.
Итоги
Скачанные url в итоге заняли 10гб,и воркеры приблизительно работали около 16-20 часов,а в конце месяца пришел счет, аж на 2.52 бакса!!!